
携手DeepSeek,助力Smart Brain行业大模型焕新升级!
2025年开年,AI圈最火的事件,当属DeepSeek-R1发布,业界目光均聚焦于此。那么DeepSeek-R1为何能吸引力全世界的目光?到底做了什么创新,有哪些特点?DeepSeek还需要提示词吗?美国为什么要打压DeepSeek?接下来我们逐一分析。
一、DeepSeek迅速占领国内外市场
DeepSeek是一款由国内团队开发的高性能多模态AI模型,使用数据蒸馏技术,以得到更为精炼、有用的数据,其强大的推理能力和高效的训练机制受到广泛关注。
DeepSeek从第一个版本发布到轰动AI圈仅用了短短一年时间,让我们一起看看DeepSeek的发展历程:
2024年12月26日晚
2025年1月31日
2025年2月5日

二、DeepSeek-R1究竟强在何处?
当 DeepSeek-V3发布时,市场反应或许只是“还可以”。但R1一经推出,市场瞬间被惊艳。DeepSeek的APP在多个国家和地区的下载量超越了ChatGPT。R1不仅能力与昂贵的o1相当,推理思路甚至超越人类。那么,R1与普通AI大模型的差异究竟在哪?
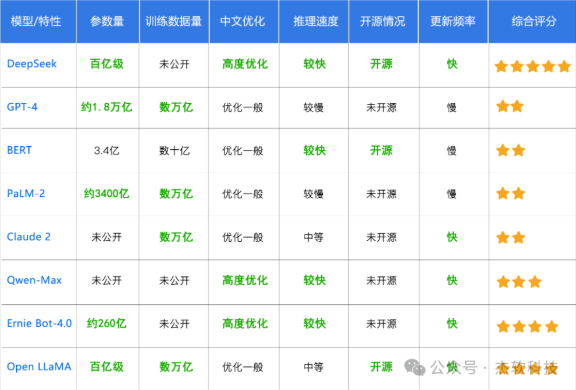
从上表可以看出,与其他大模型相比,DeepSeek在保持参数规模适中的同时,凭借其更强的中文适应能力,更快的推理速度和开源特性,迅速吸引了大众的眼球。
实际上,R1的诸多优势,根本原因在于模拟了人类的“慢速思考”模式,养成了仔细思考后再输出答案的习惯。在探讨DeepSeek-R1的“慢速思考”前,先通过以下表格了解下“快速反应”与“慢速思考”的概念
COT链式思维的出现将大模型分为了“快”、“慢”两类,用提示词引导 AI 大模型进行分步思考:前者适合快速反馈,处理即时任务;后者通过推理解决复杂问题。了解它们的差异有助于根据任务需求选择合适的模型,实现最佳效果。
三、DeepSeek-R1的特点及优势
此外,DeepSeek-R1还具备融合MoE混合专家系统、脱离英伟达CUDA、数据蒸馏、对硬件配置要求较低等特点。
.MoE混合专家系统
混合专家系统(Mixture of Experts, MoE)是一种机器学习架构,它通过整合多个“专家”模型的预测结果来提高大模型的整体性能。每个专家模型通常专注于处理输入空间的一个特定子集,门控网络(gating network)则负责根据输入数据来决定哪个或哪些专家模型的输出对最终预测结果贡献最大。
.脱离英伟达CUDA框架
DeepSeek通过使用PTX语言进行开发,绕过了英伟达的CUDA框架,增强了其在不同硬件平台上的灵活性和自主性,降低对特定供应商的依赖和成本,且有助于DeepSeek更好地兼容国产GPU芯片。
.使用数据蒸馏技术
与众多AI大模型一样,DeepSeek也使用数据蒸馏技术对其数据进行处理,旨在将原始的、复杂的数据集进行提炼和浓缩,得到更为精炼、紧凑、易于处理的数据集,直观的体现在参数变小,但同时保留关键信息和特征。
以DeepSeek-R1-Distill-1.5B这个模型为例,它是将DeepSeek的知识蒸馏到1.5B模型上。严格来说,这个模型已不能完全等同于DeepSeek模型,而是DeepSeek把自身知识传授给了R1模型,从而增强了原本模型的能力。
因此,DeepSeek的这种训练方式,在实现比肩o1效果的同时大幅降低成本,并且选择开源,这一成果震动全球科技圈,也是美国科技巨头纷纷指责和打压DeepSeek的重要原因。
.通过强化学习(RL)降低训练成本
OpenAI等大模型采用有监督微调(SFT)与强化学习(RL)相结合的混合训练方式,对数据质量和算力要求颇高。而DeepSeek首次证明了仅通过纯强化学习(RL)进行训练的可行性。借助这种训练方式,DeepSeek的模型能够自我进化,自发涌现出反思、长链推理等能力。
.对算力要求极低
DeepSeek-R1开放了多个蒸馏版本的模型,还是以最小参数的DeepSeek-R1-Distill-Qwen-1.5B为例,该模型仅有15亿参数,对显卡要求极低,仅需4G显存便能运行,这意味着个人手机和笔记本电脑都可以轻松部署。别看它参数小,推理性能却能达到GPT4o级别。
四、DeepSeek还需要提示词吗?
其实,使用 DeepSeek-R1依然需要提示词,只是使用门槛降低了。我们无需特意在提示词中教导模型思考,因为它可能比我们思考得更好,一开始就教它思考反而可能限制它。
所以,要充分发挥 DeepSeek的作用,同样需要掌握提示词技巧。使用 DeepSeek时,我们可以先尝试简单提示词,若无法满足需求,再逐步使用复杂提示词。
五、深度融合,全新启程
Smart Brain作为杰软科技的AI行业大模型开发平台,借DeepSeek-R1正式发布之机,率先完成了与DeepSeek-R1-8B、DeepSeek-R1-32B两个版本的对接,进一步优化了平台性能、降低了用户使用门槛、为更多业务应用场景开展提供可能。
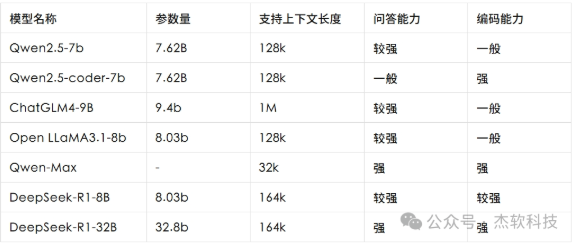
截至当前,Smart Brain已成功接入七个开源模型:
.强化AI数据分析能力
Smart Brain大模型应用开发平台内嵌多种开源大模型,通过多源数据采集及治理,结合私有化数据训练,为不同需求的企业级用户提供多个个性化AI应用场景。此次与DeepSeek-R1的强强联合,将进一步加强Smart Brain的中文分析能力和本地轻量化部署优势。
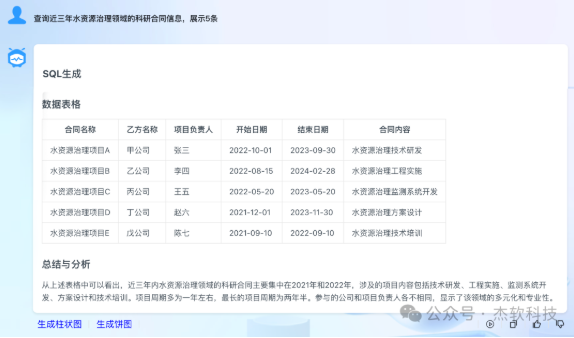
Smart Brain的最大特点及优势在于使用企业私有数据进行数据训练,并与AI大模型相结合实现数据分析,表现出通识性大模型无法达到的特性,如以某科研单位私有数据训练结果为例:查询近三年水资源治理领域的科研合同信息,并按部门维度以图表形式展现,Smart Brain将之变为可能。

.引入AI辅助编程工具
Cursor与DeepSeek-V3组成的工具集成了先进的代码生成、补全和错误检测功能,旨在提升开发者的编程效率和代码质量。DeepSeek-V3的强大算法能够理解编程语言的复杂结构,提供精准的代码建议和优化方案,而Cursor的直观界面则使得与AI的交互变得无缝且自然。
开发者可以通过简单的指令或代码片段,快速获得完整的代码块,减少重复性工作,专注于更具创造性的编程任务。此外,这种AI辅助工具还能学习用户的编程习惯,提供个性化的编程体验,从而在软件开发过程中实现更高效的合作。
杰软科技Smart Brain(智博)人工智能一体机与DeepSeek的强强联手,全面助力企业级行业大模型应用降本增效,期待您的垂询。
